Most engineers think...
Most candidates describe Akamai Content Protector AI Crawler Control as a product name and stop there. That is not enough for L2/L3 work.
The better model is operational: know the components, follow the flow, prove the policy hit, and explain the failure path. For this topic, the core idea is Crawler identity, category and path-level mitigation policy.
① What it solves and where it sits
AI and commercial crawlers can stress sites, copy content or violate business terms. Security teams need a policy model that separates trusted indexing from unwanted extraction.
Production use case: Use it when marketing, legal and security need a defensible response to AI crawler traffic and aggressive scraping.
Best one-line description of Akamai Content Protector AI Crawler Control?
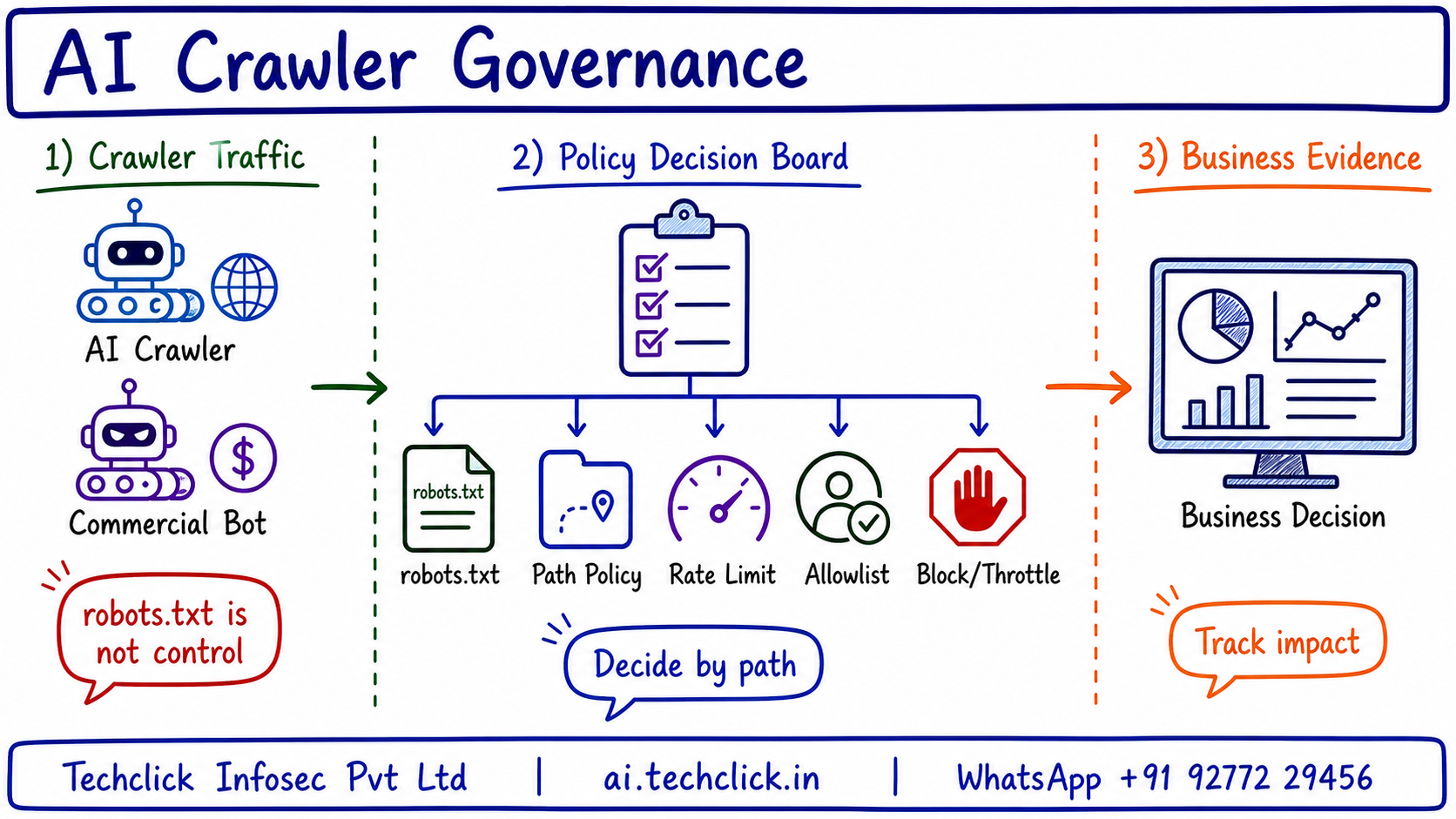
② Core components you must name
Use these names before jumping to troubleshooting. They anchor the architecture and make the interview answer sound practical.
- Crawler identity — Distinguishes known, unknown, commercial and AI crawlers
- Path policy — Applies different decisions by content value and sensitivity
- Rate control — Reduces scraping load without breaking legitimate indexing
- Allowlist/exception — Keeps approved partners or search engines working
- Business decision — Captures legal, licensing or monetization context
Say the path in order: Classify bot → Check path → Apply rate → Decide action → Track impact. It keeps the answer structured.
A decision is not real until logs/events show the rule, object and final action.
Most outages are not product magic; they are forwarding, health, identity, certificate or rule-order problems.
Safe rollout: Inventory crawler traffic first, agree business exceptions, throttle before block where risk is unclear, and monitor revenue or SEO impact.
Lead with Crawler identity, Path policy, Rate control. It sounds like production work, not brochure reading.
Which item belongs in the core architecture?
③ The traffic or telemetry path
The healthy path is: Classify bot → Check path → Apply rate → Decide action → Track impact. Walk it left to right. If a user report says 'it is broken', locate the exact stage where evidence stops.
The primary control is: Validate crawler identity, category, path, rate, action, allowlist and business decision.
If Classify bot never reaches the control point, no later policy can help. Confirm steering/forwarding first.
▶ Watch the Akamai Content Protector AI Crawler Control decision path
Press Play for the healthy path, then Break it for the common outage.
What should you trace first during troubleshooting?
④ Operations, rollout and interview response
The safe rollout answer is: Inventory crawler traffic first, agree business exceptions, throttle before block where risk is unclear, and monitor revenue or SEO impact. That prevents broad production impact while still moving toward enforcement.
Compared with robots.txt as the only control, the value is richer policy context, better visibility and a clearer operational evidence trail.
Rohan at a Noida SOC gets this ticket
AI crawler traffic spikes on paid training content and origin load increases.
The site relied on robots.txt and had no crawler category, path or monetization decision.
Trace Classify bot → Check path → Apply rate → Decide action → Track impact, then compare policy logs, object health and user scope.
Console ▸ policy/logs ▸ health/status ▸ affected user testClassify the crawler, validate affected paths and rates, choose throttle/block/allow with business approval, and watch logs for side effects.
Repeat the original user test and capture the allow/block/health evidence in logs.
The final answer should include log evidence, health state and a user test. That is what separates RCA from guessing.
Safest production rollout answer?
🤖 Ask the AI Tutor
Tap any question — instant, scoped to this lesson. No login, no waiting.
Pre-curated from vendor docs + community Q&A, scoped to this lesson. For a live prod issue, paste your export into chat.techclick.in.
📝 Wrap-up assessment — six more
You've answered 4 inline. Six left. 70% (7 of 10) marks the lesson complete on your profile. Tap Submit all answers at the end.
🧠 In your own words
Explain Akamai Content Protector AI Crawler Control in one L2 interview sentence.
🗣 Teach a friend
Best way to lock it in — explain it in one line to a teammate. Tap to generate a paste-ready summary.
📖 Glossary
- Security policy
- The Akamai policy object that decides alert, deny, exception and control behavior.
- ASE
- Adaptive Security Engine, the request-risk analysis layer used by Akamai WAAP controls.
- Bot score
- A value used by bot controls to distinguish likely automation from likely human sessions.
- DataStream
- Akamai streaming log export path used for SIEM and data-lake evidence.
- GRE
- Generic Routing Encapsulation tunnel used in many routed DDoS clean-traffic designs.
- Label
- Guardicore segmentation metadata used to group workloads and build policy.
📚 Sources
What's next?
Next, pair this lesson with the new Akamai Content Protector AI Crawler Control interview Q&A page and explain the same flow out loud in 90 seconds.